クラスター分析とは?顧客を分類する手法とCX向上の活用事例をわかりやすく解説
更新日:2026.02.18

エモーションテック 編集部
NPS活用やCX向上のためのお役立ち情報を発信しています。
CX(カスタマーエクスペリエンス)推進部門やマーケティング担当の皆様は、日々NPS®(ネット・プロモーター・スコア)をはじめとする顧客アンケートの実施や、VoC(顧客の声)の収集・分析を行うなど、CXマネジメント(CXM)に取り組まれていることと存じます。
この記事では、「顧客の多様性」をデータに基づいて解き明かし、効果的なアクションに繋げるための強力な統計的手法である「クラスター分析」について、基礎知識から具体的な実践ステップ、CX領域での活用事例まで、徹底的に解説します。
この記事のポイント
- 「クラスター分析」の基礎(似た顧客を分類する仕組み)が理解できる。
- なぜ「平均的な顧客像(ペルソナ)」ではCX改善が失敗するのか、その理由と解決策がわかる。
- 階層クラスター分析と非階層クラスター分析の違いや、実務での使い分けが明確になる。
- NPSや行動データを組み合わせ、具体的な改善アクションに繋げるための実践ステップを習得できる。
目次
EmotionTechのNPS分析・CX関連サービスがわかる資料(概要・支援実績)をダウンロードする
クラスター分析とは?似たもの同士を見つける統計的手法
クラスター分析(Cluster Analysis)とは、様々な特徴や性質を持つデータ(個体や変数)の中から、互いに「似ている」もの同士を集めてグループ(クラスター:集団、群れ)に分類する統計的な分析手法の総称です。
マーケティングリサーチの分野では、市場や顧客を特定の基準で分類する「セグメンテーション(市場細分化)」を行う際の代表的な手法として広く活用されています。
ここで混同されがちなのが「セグメンテーション」と「クラスター分析」の違いです。
「セグメンテーション」は市場や顧客を分類する「目的・行為」そのものを指します。一方、「クラスター分析」は「セグメンテーション」を行うための「数学的な手法(手段)」の一つです。年代や性別で分けることも「セグメンテーション」ですが、データに基づいて似たもの同士を集める手法がクラスター分析です。
アパレルECサイトの利用客を例にとると、
- 閲覧履歴や購入サイクル、レビュー内容などをクラスター分析にかけることで、流行のアイテムをいち早くチェックし、定価でも購入する『トレンド先取りグループ』
- 失敗したくない意識が強く、レビューやランキングを熟読してから購入する『慎重・納得重視グループ』
- セール時期やクーポン配布時のみまとめ買いをする『価格メリット追求グループ』
といった、属性データだけでは見えない心理や行動パターンに基づく顧客セグメントを発見することができます。
このように、一見するととらえどころがないように見えるデータでも、クラスター分析を用いることで、その背後にある構造や共通点を持つグループを浮かび上がらせることが可能になります。
なぜCX向上においてクラスター分析が重要なのか?
特にCX向上においては、クラスター分析は「顧客理解の解像度」を飛躍的に高め、勘や経験だけに頼らないデータドリブンな施策立案を実現する重要な分析手法となります。この重要性について、3つの側面から解説します。
1. 顧客の「顔」を具体的に描き出す(ペルソナの精度向上)
「当社の平均的な顧客は、40代男性で…」といった、曖昧で平均的な顧客像(ペルソナ)を想定してマーケティング施策を考えても、多くの場合うまくいきません。現実には「平均的な顧客」など存在せず、多様なニーズを持つ顧客の集合体だからです。
クラスター分析を用いることで、「平均」に隠れて見えにくくなっていた、特徴的な顧客グループをデータに基づいて定義できます。例えば、「サービスAには高い満足度を示しているが、サポート体制には不満を持つグループ」や、「価格には満足しているが、新機能の利用率が極端に低いグループ」など、具体的な顧客セグメントを描き出すことができます。これにより、各グループの特徴を具体的に思い浮かべながら、より的確なコミュニケーションやCX改善策を検討できるようになります。
2. アプローチすべき対象を明確化する(ターゲティングの最適化)
CX向上のためには、限られたリソース(予算、人員、時間)を効果的に配分する必要があります。クラスター分析は、どこにリソースを集中投下すべきかを判断するための強力な羅針盤となります。
例えば、NPSと他の変数(利用頻度、利用期間、問い合わせ回数など)を組み合わせて分析することで、「NPSは高いが購買頻度が低い(推奨はするが買ってはいない)グループ」や、「NPSは低いが利用歴が長く、問い合わせも多い(不満を抱えながらも使い続けている)グループ」など、特定の課題を持つクラスターを発見できます。
前者のグループにはアップセルやクロスセルの機会が、後者のグループには早急なサポート体制の見直しや機能改善のニーズが潜んでいる可能性があります。このように、アプローチすべき優先度の高いセグメントを浮かび上がらせることで、施策の的を絞ることが可能になります。
3. LTV(顧客生涯価値)の最大化に貢献する
企業の持続的な成長には、新規顧客の獲得だけでなく、既存顧客との長期的な関係性を構築し、LTVを高めることが不可欠です。
クラスター分析によって、自社にとって最も価値の高い「ロイヤルティの高い優良顧客クラスター」の特徴(どのようなニーズを持ち、どのタッチポイントに満足しているか)を明らかにすることができます。その特徴を理解することで、そのクラスターを維持・拡大するための施策(例:特別な優待プログラムの提供、コミュニティへの招待)や、他の顧客をそのクラスターに引き上げるための育成(ナーチャリング)戦略を立てることができます。
同時に、「解約リスクの高いクラスター」の特徴を把握し、その予兆(利用頻度の低下、特定のネガティブなトピックへの言及など)を早期に察知することで、先回りしたリテンション(解約防止)施策を講じ、顧客離れを防ぐことにも繋がります。
関連記事:
LTVとは?計算方法と向上させるための秘訣
クラスター分析の主な手法と選び方
クラスター分析には様々なアルゴリズム(計算手法)が存在しますが、ビジネスの実務でよく使われるのは、大きく分けて「階層クラスター分析」と「非階層クラスター分析」の2種類です。分析の目的やデータの量、特性に応じて、これらの手法を適切に使い分けることが重要です。
階層クラスター分析(Hierarchical Cluster Analysis)
階層クラスター分析は、似ているサンプル(顧客など)から順にまとめていく(あるいは、最初は一つだった集団を分割していく)ことで、最終的に一つの大きなクラスターになるまでの「階層構造」を作る手法です。分析結果は、樹形図(デンドログラム)と呼ばれるトーナメント表のような図で視覚化されます。
樹形図を見ることで、どのサンプル同士がどれくらい似ている(近い距離で結合している)のか、また、全体をいくつのクラスターに分けるのが妥当そうかを視覚的に判断することができます。
例:階層クラスター分析(デンドログラム)
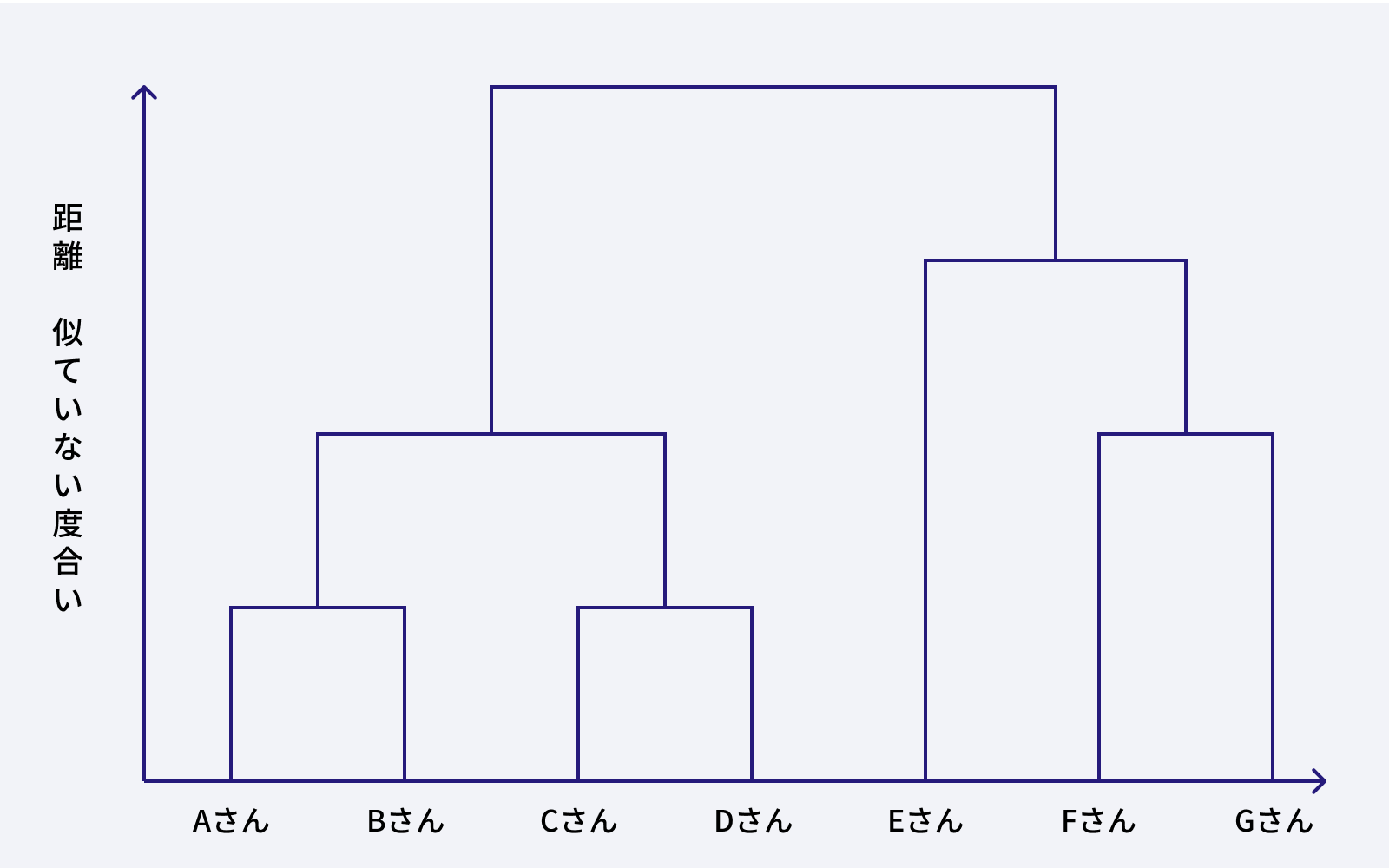
顧客が似ている順に、どのようにグループ(クラスター)にまとまっていくかを表した樹形図です。縦軸が「似ていない度合い(距離)」です。下の方で繋がっているほど似ている顧客(例:AさんとBさん)であることを示します。どの高さで「切る」かによって、グループの数が変わる様子が視覚的に分かります。
代表的な手法(距離の計算方法)
- ウォード法(Ward’s method): クラスター内のばらつき(平方和)が最小になるように結合していく方法。最も一般的に使われる手法の一つで、比較的きれいなクラスターが形成されやすいとされています。
- 群平均法(Group average method): 2つのクラスターに含まれる全サンプル間の距離の平均値を用いて結合する方法。
- 最短距離法(単連結法): 2つのクラスター間で最も近いサンプル間の距離で結合する方法。
データの特性に応じて手法を選ぶことが大切です。
非階層クラスター分析(Non-Hierarchical Cluster Analysis)
非階層クラスター分析は、あらかじめ「いくつのクラスターに分けるか」を分析者が決めておき(例:3つに分ける)、その数になるようにサンプルを分類する手法です。階層構造は作らず、各サンプルはいずれか一つのクラスターに所属します。
代表的な手法である「k-means法(k平均法)」が非常に有名で、実務でも頻繁に用いられます。
例:非階層クラスター分析(散布図)
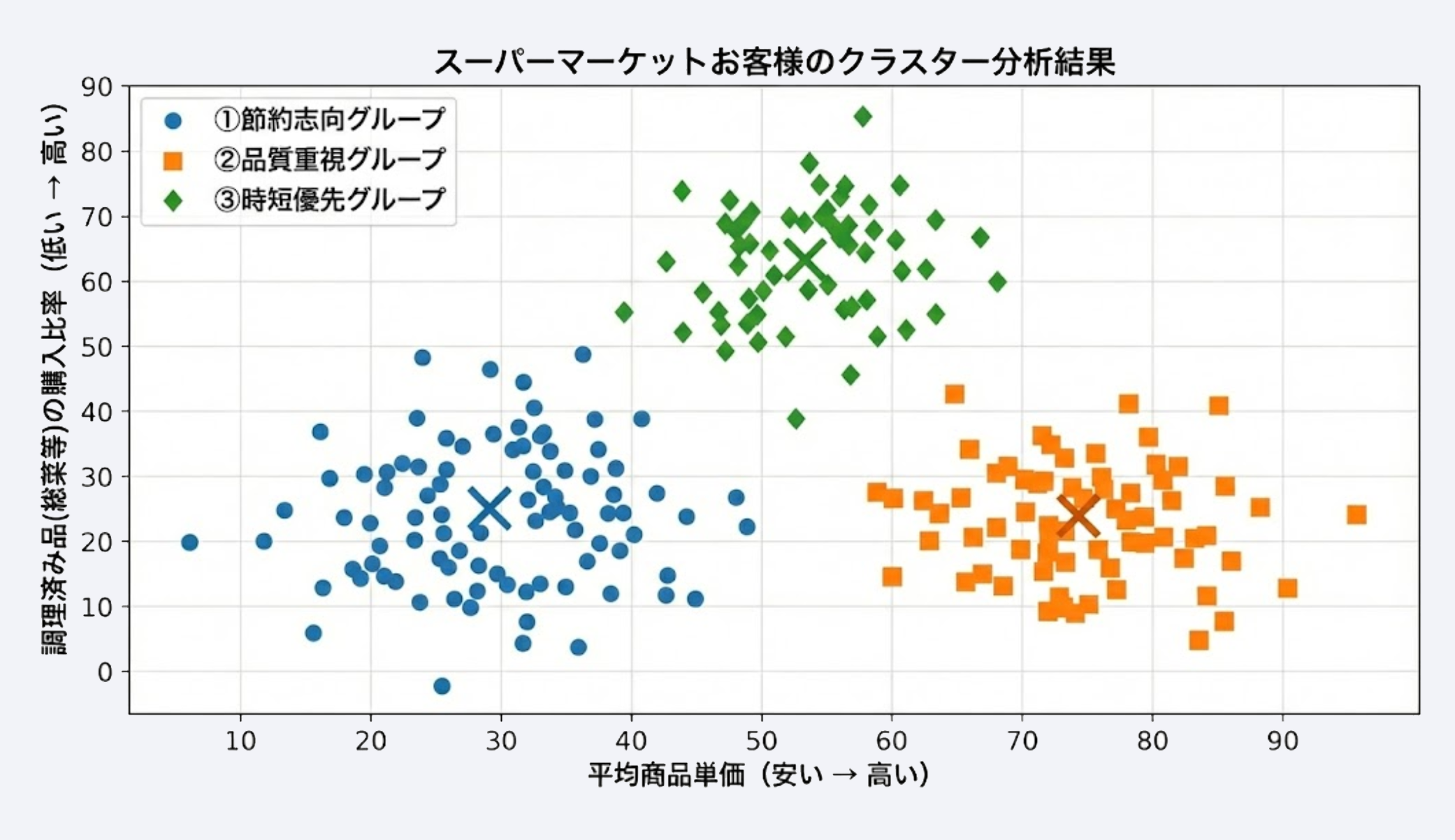
多数の顧客データを、設定した軸(平均商品単価 × 調理済み品購入比率)に基づいて、あらかじめ決めた「3つのグループ」に分類した結果のイメージです。それぞれのグループの中心(代表的な点)を「×」印で示しています。
- 青色(●)節約志向グループ: 「単価が安い」かつ「調理済み品が少ない(自炊派)」エリアに集まっています。
- オレンジ色(■)品質重視グループ: 「単価が高い」かつ「調理済み品が少ない(自炊派)」エリアに集まっています。
- 緑色(◆)時短優先グループ: 「調理済み品が多い(時短派)」エリアに集まっています(単価は中程度)。
代表的な手法
- k-means法(k平均法): 最も代表的な非階層クラスター分析の手法。指定したクラスター数(k個)に基づき、各クラスターの中心(重心)からの距離が最も近くなるように、サンプルを割り当てていく処理を繰り返します。
どちらの手法を選ぶべきか?
これらの手法は、どちらが優れているというものではなく、目的やデータの状況に応じて使い分けるのが一般的です。
| 比較項目 | 階層クラスター分析 (例: ウォード法) |
非階層クラスター分析 (例: k-means法) |
| クラスター数の指定 | 不要 (デンドログラムを見て後から決める) |
必要 (事前に分析者が決める) |
| データ量 (サンプル数) |
少ない場合に適している (~数百程度) |
多い場合に適している (数千~) |
| 計算速度 | 遅い (データ量が多いと非常に遅い) |
速い |
| 分析結果の可視化 | デンドログラムで階層構造を可視化できる | 階層構造は分からない (散布図などで可視化) |
| 主な利用シーン | 探索的な分析、少数の顧客プロファイルの分類 | 大規模アンケート、購買履歴などのセグメンテーション |
実務的なアプローチとしては、まずサンプルの一部を抽出して「階層クラスター分析」を行い、デンドログラムを見て「おおよそ、いくつのクラスターに分けるのが妥当か」の当たりをつけます。その後、そのクラスター数を「非階層クラスター分析(k-means法)」に設定し、全データを使って分析を実行する、という2段階のアプローチもよく取られます。
CX担当者のためのクラスター分析 実践ステップ
では、実際にクラスター分析を用いて顧客理解を深めるためには、どのような手順を踏めばよいのでしょうか。意味のある結果を得るためには、実際の分析前後の「設計」と「解釈」が極めて重要です。CX推進担当者が実務で行う際の7つのステップを解説します。
STEP 1. 分析目的の明確化
最も重要なステップです。「なぜ」クラスター分析を行うのか、その結果を「何に」使いたいのかを明確にします。目的が曖昧なまま分析を始めても、無数の分類パターンが出てくるだけで、施策に繋がるインサイトは得られません。
(目的の例)
- NPSが低い(批判者・中立者)顧客層の共通する不満要因を発見し、優先的にCX改善を行うため。
- ロイヤルティの高い優良顧客層(推奨者)を定義し、その層を増やすためのマーケティング施策を立案するため。
- 解約予備軍となりうる顧客セグメントの特徴を把握し、リテンション施策に繋げるため。
- 新しい商品・サービス開発のヒントを得るために、潜在的なニーズを持つ顧客層を発見するため。
STEP 2. 変数の選定
目的に沿って、顧客を「分ける軸」となる変数を決めます。この変数の選び方(何を分析データに含めるか)で、分析結果の質が大きく変わります。分析の「肝」とも言えるステップです。
クラスター分析に用いる変数は、大きく以下の3つに分類されます。CX分析においては、これらを組み合わせることが顧客の多面的な理解に繋がります。
変数の例
| データの種類 | 具体的な項目・例 |
|---|---|
| デモグラフィック (属性)データ |
年齢、性別、居住地(エリア)、職業、家族構成、利用年数(顧客歴)など。 (例:「20代・女性・利用歴半年未満」) |
| 行動データ (客観的) |
購買頻度、累計購買金額、直近購買日(Recency)、利用サービスの種類、Webサイト閲覧履歴(訪問頻度、閲覧ページ)、アプリ起動回数、サポートへの問い合わせ回数など。 (例:「月1回以上購入」「サポートへの問い合わせが多い」) |
| 心理・意識データ (主観的・アンケート) |
NPS、CES(顧客努力指標)、CSAT(顧客満足度)、各タッチポイント(商品、価格、サポート、Webサイトなど)の満足度、推奨/非推奨理由、重視する価値観、ブランドイメージなど。 (例:「NPSが低い」「価格よりも品質を重視」「サポートの対応に不満」) |
属性データ(年齢、性別など)だけでわける、CX改善に繋がるインサイトは得られにくいでしょう。
関連記事:
NPS調査の作り方を解説!アンケートの作成や調査設計のコツがわかる
STEP 3. データの収集と前処理
選定した変数に基づいて、社内のデータベース(CRM、購買履歴、アンケートシステムなど)からデータを収集します。収集したデータは、そのまま分析に使えることは稀で、「前処理」と呼ばれる準備作業が必要です。データの特性に応じた処理を行うことが分析を行う上で非常に大切です。
- 欠損値の処理: アンケートの無回答やデータ不備(空白)をどう扱うか(除外する、平均値で補完するなど)を決めます。
- 外れ値の確認: 極端にかけ離れた値(例:購買金額が異常に高い)が分析結果に悪影響を与えないかを確認し、必要に応じて処理します。
- 尺度の統一(標準化): クラスター分析では、変数間の「距離」を計算します。「購買金額(円)」と「満足度(5段階評価)」のように単位や尺度が全く異なる変数をそのまま使うと、値の大きい「購買金額」の影響だけが強く出てしまいます。これを防ぐために、「標準化」などの処理を行い、全てを統一された『ものさし』に合わせる処理を行います。
STEP 4. 分析手法の選択
STEP 3で準備したデータと分析の目的に基づき、前述した「階層クラスター分析」と「非階層クラスター分析」のどちらを使うか(あるいは併用するか)を決定します。
- データ量が数百件程度で、どのようなグループがありそうか探索的に見たい場合 → 階層クラスター分析
- データ量が数千件以上あり、分けるべきクラスター数にある程度の見当がついている場合 → 非階層クラスター分析(k-means法)
STEP 5. クラスター数の決定
分析において、最も悩ましいステップの一つが「クラスター数をいくつにするか」です。絶対的な正解はなく、統計的な妥当性と、施策に繋がる「解釈のしやすさ」のバランスで決定します。
- 階層クラスター分析の場合:デンドログラムを見て、縦軸の「距離」が急に長くなっている(似ていないもの同士が結合している)箇所の少し手前で切る、という判断をします。
- 非階層クラスター分析(k-means法)の場合:エルボー法(Elbow Method)と呼ばれる補助的な手法がよく使われます。クラスター数を1つずつ増やしながら分析を実行し、各クラスター内のばらつき(SSE:誤差平方和)がどれだけ減少したかをグラフにプロットします。グラフが「肘(Elbow)」のように急激に曲がる(減少幅が鈍化する)点が、最適なクラスター数(k)の候補とされます。
ただし、統計的に最適とされる数が、必ずしも実務的に意味のある分類になるとは限りません。クラスター数が多すぎると(例:10個)、各グループの特徴が曖昧になり、施策を考えるのが困難になります。ビジネスの現場では、3~6個程度のクラスターに分けるのが、解釈しやすく、アクションにも繋がりやすいとされています。
STEP 6. 分析の実行とクラスターの解釈(プロファイリング)
分析手法とクラスター数を決定したら、統計ソフト(SPSS, R, Pythonなど)やBIツールに搭載された分析機能を使って分析を実行します。
重要なのは、出力された結果(各クラスターに属するサンプル数、各変数の平均値一覧など)を見て、それぞれのクラスターが「どのような顧客グループなのか」を深く解釈(プロファイリング)することです。
単に平均値の差を見るだけでなく、クロス集計表を作成したり、属性データや行動データとアンケート結果を掛け合わせたりしながら、各クラスターの「ペルソナ」を具体的に描き出します。
そして、そのクラスターの特徴を最もよく表す「名前(ネーミング)」を付けます。
(例:「価格重視・低NPSグループ」「サポート活用・高ロイヤルティグループ」「新機能期待・中立者グループ」)
この解釈のプロセスで、アンケートのフリーアンサーや、コールセンターへの入電内容、営業担当者の日報といった「定性データ」と突き合わせることで、なぜそのクラスターがそのような評価や行動をとるのか(Why)がより深く理解でき、施策のヒントが得られます。
STEP 7. 施策(アクション)への反映
クラスター分析は、分類して「面白かったね」で終わってしまっては意味がありません。分析結果は、必ずCX改善の「次の一手」に繋げる必要があります。
STEP 6で定義した各クラスターの特性、ニーズ、課題感に合わせて、最も効果的と考えられるアプローチを検討し、実行に移します。
- 「価格重視・低NPSグループ」→ コストパフォーマンスの高さを改めて訴求する情報を提供する。一方で、この層への過度な投資は抑制する。
- 「サポート活用・高ロイヤルティグループ」→ 手厚いサポート体制がロイヤルティの源泉であると仮説立て、サポート品質をさらに向上させる。また、彼らの成功事例を他の顧客に共有してもらう(コミュニティへの参加促進、事例インタビューなど)。
- 「新機能期待・中立者グループ」→ 新機能のベータ版テストに招待し、フィードバックを得ることでエンゲージメントを高め、推奨者への転換を図る。
施策を実行した後は、必ず効果測定(例:対象クラスターのNPSや利用頻度がどう変化したか)を行い、次の分析と改善サイクル(PDCA)に繋げていくことが重要です。
クラスター分析のマーケティング・CX活用事例と成功のポイント
クラスター分析は、正しく設計し、深く解釈すれば、CX改善やマーケティング戦略において非常に強力な武器となります。ここでは、具体的な活用事例と、分析を「机上の空論」で終わらせないための重要なポイントをご紹介します。
活用事例1:NPSスコアと利用状況で顧客セグメントを定義
あるSaaS企業では、全顧客を対象にNPS調査を実施していましたが、属性データだけでは詳細なインサイトの特定が難しく、「推奨者」「中立者」「批判者」という分類だけでは、曖昧な顧客理解に留まり、具体的なアクションに繋げにくいという課題がありました。
そこで、NPSスコア(意識)だけでなく、サービスの「ログイン頻度」「特定機能の利用率」「サポート問い合わせ回数」といった行動データを変数に加え、クラスター分析を実行しました。
その結果、以下のような特徴的なクラスターが発見されました。
| ロイヤルカスタマー群 | NPSが高く、ログイン頻度・機能利用率も高い。 (サポートも能動的に活用している) |
| サイレント・ロイヤル群 | NPSは高いが、ログイン頻度や機能利用率は低い。 (推奨はするがあまり使っていない) |
| 不満抱えた ヘビーユーザー群 |
NPSは低い(批判者)が、ログイン頻度や機能利用率は高い。 (サポートへの不満に関するVoCが多い) |
| 離反予備軍 | NPSが低く、ログイン頻度も機能利用率も低い。 |
この分析結果に基づき、各クラスターへのアプローチを最適化しました。
- (1)ロイヤル群には:新機能の先行体験や事例紹介を依頼し、更なるエンゲージメント強化を図る。
- (2)サイレント群には:活用されていない便利機能の紹介(リマインド)や、導入目的の再ヒアリングを実施。
- (3)不満ヘビーユーザー群には:サポート体制の課題(例:応答速度)を最優先で改善し、プロアクティブ(先回り)なフォローを実施。
- (4)離反予備軍には:コストをかけたリテンション施策は行わず、解約理由のヒアリングに努める。
結果として、(3)の層のNPSが大幅に改善し、全体の解約率低下にも貢献しました。
活用事例2:顧客の価値観に基づいた新サービス開発
ある食品宅配サービスでは、顧客の属性データ(年齢、性別、家族構成)や購買データ(購入商品カテゴリ)に基づいたセグメンテーションでは、顧客の多様なニーズを捉えきれないと感じていました。
そこで、「食」に対する価値観(「価格重視」「品質・安全性重視」「手軽さ・時短重視」「健康・オーガニック志向」「トレンド・新規性重視」など)に関するアンケートを実施し、その回答結果を基にクラスター分析を行いました。
その結果、従来のデモグラフィック変数では見えなかった、「エコ・サステナビリティ志向グループ」(価格は多少高くても、オーガニック素材や環境に配慮した商品、簡易包装を強く支持する層)が一定数存在することが明らかになりました。
このインサイトに基づき、そのクラスターのニーズに特化した新しい商品ライン(オーガニック野菜セット、サステナブルな製法の商品特集など)を開発・投入したところ、当該クラスターの顧客単価と継続率が大きく向上しました。
活用事例3:VoC(顧客の声)と組み合わせて解約予兆を特定
ある通信サービス企業では、解約率の高さが課題でした。利用期間や料金プラン、通信量などの行動データだけで解約予測モデルを作ろうとしましたが、精度が上がりませんでした。
そこで、コールセンターに寄せられる問い合わせ内容や、NPSアンケートのフリーアンサー(VoC)を生成AIを用いたVoCテキスト分析サービス(TopicScan)で分析し、「手続きが面倒」「サポートの返事が遅い」「料金体系が分かりにくい」「通信速度が遅い」といった不満の「種類」をトピックとして抽出し、それらを変数に加えたクラスター分析を実施しました。
その結果、行動データ(利用頻度の低下など)にはまだ表れていなくても、「サポートの応答品質」に関するネガティブなVoCを発言しているクラスターが、その数ヶ月後に極めて高い確率で解約に至っていることが判明しました。
この分析に基づき、解約の「真の先行指標」としてこのクラスターを特定し、優先的にサポート体制のオペレーション改善と、該当顧客への個別フォローを行うことで、解約率の改善に成功しました。
分析を成功させるための3つのポイント
これらの事例のように、クラスター分析をCX改善の強力なドライバーとするためには、以下の3つのポイントが不可欠です。
ポイント1:「分ける軸(変数)」に徹底的にこだわる
前述の通り、クラスター分析の結果は「何で分けたか」で決まります。「とりあえず手元にあるデータ(属性データや購買履歴)だけで分析してみる」というアプローチでは、当たり障りのない、施策に繋がらない結果になりがちです。
STEP 1で設定した「分析目的(何を明らかにしたいのか)」に立ち返り、それを知るためにはどのような「顧客の意識(アンケート)」や「行動」のデータが軸として必要なのかを、徹底的に議論して設計することが最も重要です。必要であれば、クラスター分析の軸を抽出するために、専用のアンケート調査を設計することが必要になることもあるでしょう。
ポイント2:「解釈」に時間をかける(VoCと組み合わせる)
分析ツールから出力された平均値の羅列やグラフは、クラスター分析の「結果」ではありますが、「インサイト」そのものではありません。
「なぜ、このクラスターはNPSが低いのか?」「なぜ、あのクラスターは高額商品を買ってくれるのか?」——その「Why」を、アンケートのフリーコメントやコールログなどの「定性データ」と組み合わせて深く掘り下げる「解釈」のプロセスにこそ、価値があります。
統計的な数値(定量)と、生々しい顧客の声(定性)を行き来することで、初めてそのクラスターのペルソナが具体的に見え、刺さる施策の仮説が生まれます。
ポイント3:「分類して終わり」にしない(アクションに繋げる)
クラスター分析はあくまで「手段」であり、顧客を分類すること自体が「目的」ではありません。
分析結果をCX推進部門内だけで共有し、「興味深い顧客セグメントが発見できました」で終わらせては、分析にかけたリソースが全て無駄になってしまいます。分析結果(=各クラスターの特徴と課題)を、マーケティング部門、営業部門、サポート部門、商品開発部門など、実際のアクションを実行する現場の担当者に「翻訳」して伝えることが重要です。
「このクラスターには、こういうアプローチが効きそうだ」「あのクラスターが抱えている不満は、この業務プロセスを改善すれば解消できるはずだ」という、現場が動ける具体的な「次の一手」に落とし込み、実行し、その結果をまたデータで検証するサイクルを回すことを支えることこそが、CX推進部門のミッションであり、クラスター分析の活用のゴールです。
関連記事:
アンケートでよく使う分析手法 | 基本から応用まで解説
クラスター分析に関するよくある質問(FAQ)
Q. クラスター分析とセグメンテーションの違いは何ですか?
A. 「セグメンテーション」は市場や顧客を分類する「目的・行為」そのものを指します。一方、「クラスター分析」はセグメンテーションを行うための「数学的な手法(手段)」の一つです。年代や性別で分けることもセグメンテーションですが、データに基づいて似たもの同士を集める手法がクラスター分析です。
Q. クラスターの「ネーミング(名前付け)」が難しいのですが、コツはありますか
A. 平均値が高い/低いという数値的な特徴だけでなく、そのグループを「一人の人間(ペルソナ)」として想像することがコツです。 例えば「価格感度が高い」だけでなく、定性データ(VoC)を見て「なぜ高いのか(節約志向なのか、価値に見合わないと感じているのか)」まで深掘りします。「〇〇で悩み中の××さん」のように、社内の誰もがイメージを共有できるような、人間味のある名前をつけると施策立案がスムーズになります。
Q. 分析した結果、「特徴のないクラスター」ができてしまったのですが、失敗ですか?
A. 必ずしも失敗ではありません。「平均的でこれといった特徴がない層」がボリュームゾーンとして存在すること自体が、一つの重要な発見です。 ただし、全てのクラスターが似たり寄ったりになってしまった場合は、「変数の選び方」に問題がある可能性があります。似たような変数ばかり選んでいないか、あるいは顧客を区別する決定的な要因(キラー変数)が含まれていないかを見直し、再分析することをお勧めします。
Q. クラスター数(グループ数)を統計的に決める正解はありますか
A. 統計的に「最適な数」を示唆する指標(シルエット係数など)は存在しますが、ビジネスの実務においては「解釈しやすく、アクション可能な数」にすることが優先されます。 例えば統計的に「10個」が最適と出ても、現場で10通りの施策を打ち分けるリソースがなければ意味がありません。一般的には、人間の認知範囲で扱いやすい3〜6個程度に設定されるケースが多く、統計的な指標はあくまで「目安」として扱います。
まとめ
本記事では、顧客理解の解像度を高め、データに基づいたCX改善アクションを導き出すための「クラスター分析」について、その基礎から実践的なステップ、活用事例までを詳細に解説しました。最後に、重要なポイントをまとめます。
- クラスター分析は、多様な顧客の中から「似たもの同士」のグループ(クラスター)を見つけ出す統計的手法であり、CX向上において画一的なアプローチから脱却し、顧客理解を深めるために不可欠です。
- 分析手法には、サンプル数が少ない場合や探索的な分析に適した「階層クラスター分析」と、大規模データに適した「非階層クラスター分析(k-means法など)」があり、目的に応じて使い分けます。
- 分析の成功は、「何のために分析するか(目的)」と「どの軸で分けるか(変数)」の設計でほぼ決まります。特にCX分析では、NPSやVoCなどの感情データと購買履歴やWEBアクセスデータなどの行動データを組み合わせることが極めて重要です。
- 分析結果は、統計的な数値だけでなく、VoC(定性データ)と組み合わせて深く「解釈」し、具体的な「アクション(施策)」に繋げて初めて価値を生みます。分類して満足せず、現場が動ける「次の一手」に落とし込むことがゴールです。
EmotionTechCX資料を
ダウンロードする
このサービス資料でわかること
- EmotionTechCXのサービス概要
- EmotionTechの独自分析技術
- 各種プランの内容
- 導入事例



